
LandSlide4Sense
Landslide detection through semantic segmentation on the Landslide4Sense dataset
Authors
- Reiko Lettmoden
- Amit Amit
Dataset
The dataset used in our experiments is Landslide4Sense for semantic segmentation to detect landslides. The 128x128 images are collected from diverse geographical regions and the Landslide4Sense dataset has three splits, training/validation/test, consisting of 3799, 245, and 800 image patches, respectively. Each image patch is a composite of 14 bands that:
- Multispectral data from Sentinel-2: B0, B1, B2, B3, B4, B5, B6, B7, B8, B9, B10, B11.
- Slope data from ALOS PALSAR: B12.
- Digital elevation model (DEM) from ALOS PALSAR: B13.

The dataset is highly imbalanced with 98% pixels belonging to the background class and 2% belonging to the landslide class, as seen in the figure above from Ghorbanzadeh et al.. We use 50% of the train data due to computation constraints and split it into train, validation and test.
Model(s)
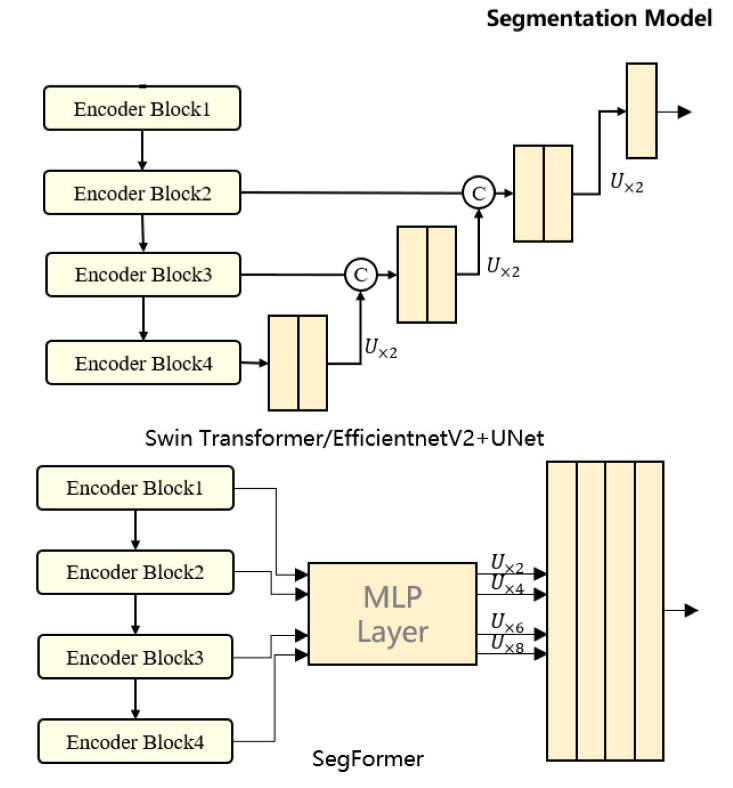
We follow the outcome of the challenge (Ghorbanzadeh et al.) such that the UNet is employed as baseline and as more powerful architectures the SegFormer and UNet with a Swin Transformer backbone, which are visualized in the figure above.
Results
Our detailed report and results with all experimental configurations can be found here.
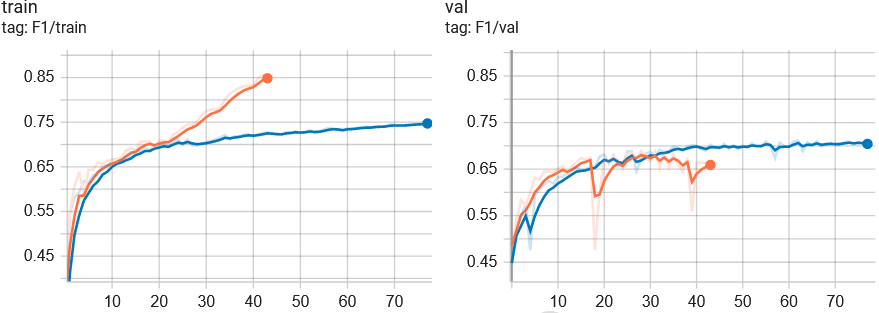
Selecting a subset of all 14 bands does not yield an improvement, however just selecting RGB bands from Sentinel-2 and both bands from ALOS PALSAR achieve almost as good F1-Score as all 14 bands. An UNet trained with augmentations (blue) overfits less to the train data in comparison to the model without augmentation (orange), as seen in the tensorboard below. This which allows us to train our models longer (early stopping later in the training stage) and leads to better generalizability.
Since the data is highly imbalanced, losses such as the Lovasz loss and WCE allow the model to better learn from minority classes. As seen in the figures below, an UNet trained with WCE (bottom) achieves higher recall than an UNet trained with CE (top) but also predicts more false positives (lower precision).


The Lovasz loss finds a good precision-recall tradeoff and thus achieves the highest F1-Score of all loss configurations. More powerful architectures such as a UNet with Swin Transformer backbone and SegFormer overfit more to the training data, such that more data might be needed to train these architectures. Hence, all in all a UNet trained with augmentations and Lovasz loss achieves the best F1-Score of all employed models.
| Bands | Augmentations | Loss | Model | F1-Score |
|---|---|---|---|---|
| ALL | - | CE | UNet | 0.721 |
| RGB Height | - | CE | UNet | 0.718 |
| ALL | + | CE | UNet | 0.736 |
| ALL | + | Lovasz | UNet | 0.756 |
| ALL | + | Lovasz | SwinT UNet | 0.745 |